
Using information technology to make data useful is as old as the Information Age. The difference today is that the volume and variety of available data has grown enormously. Big data gets almost all of the attention, but there’s also cryptic data. Both are difficult to harness using basic tools and require new technology to help organizations glean actionable information from the large and chaotic mass of data. “Big data” refers to extremely large data sets that may be analyzed computationally to reveal patterns, trends and associations, especially those related to human behavior and interaction. The challenges in dealing with big data include having the computational power that can scale to the processing requirements for the volumes involved; analytical tools to work with the large data sets; and governance necessary to manage the large data sets to ensure that the results of the analysis are accurate and meaningful. But that’s not all organizations have to deal with now. I’ve coined the term “cryptic data” to focus on a different, less well known sort of data challenge that many companies and individuals face.
Cryptic data sets aren’t easy to find or aren’t easily accessed by people who could make use of them. Why “cryptic?” As a scuba diver, I donate time to Reef Check by doing scientific species counts in and around Monterey Bay, Calif. Cryptic organisms are ones that hide out deep in the cracks and crevices of our rocky reefs. Finding and counting them accurately is time-consuming and requires skill. Similarly, it’s difficult to locate, access and collect cryptic data routinely. Because it’s difficult to locate or access routinely, those who have it can gain a competitive advantage over those who don’t. The main reason cryptic data is largely untapped is cost vs. benefits: The time, effort, money and other resources required to manually retrieve it and get it into usable form may be greater than the value of having that information.
By automating the process of routinely collecting information and transforming it into a usable form and format, technology can expand the range of data available by lowering the cost side of the equation. So far, most tools, such as Web crawlers, have been designed to be used by IT professionals. Data integration software, also mainly used by IT departments, helps transform the data collected into a form and format where it can be used by analysts to create mashups or build data tables for analysis to support operational processes. Data integration tools mainly work with internal, structured data and a majority have little or no capability to support data acquisition in the Web. Tools designed for IT professionals are a constraint in making better use of cryptic data because business users are subject matter experts. They have a better idea of the information they need and are in a better position to understand the subtleties and ambiguities in the information they collect. To address this constraint, Web scraping tools (what I call “data drones”) have appeared that are designed for business users. They use a more visual user interface design and hide some of the complexity inherent in the process. They can automate the process of collecting cryptic data and expand the scope and depth of data used for analysis, alerting and decision support.
Cryptic data can be valuable because when collected, aggregated and analyzed, it provides companies and individuals with information and insight that were unavailable. This is particularly true of data sets gathered over time from a source or combination of sources that can reveal trends and relationships that otherwise would be difficult to spot.
Cryptic data can exist within a company’s firewall (typically held in desktop spreadsheets or other files maintained by an individual as well as in “dark” operational data sets), but usually it is somewhere in the Internet cloud. For example, it may be
- Industry data collected by some group that is only available to members
- A composite list of products from gathered from competitors’ websites
- Data contained in footnotes in financial filings that are not collected in tabular form by data aggregators
- Tables of related data assembled through repetitive queries of a free or paid data source (such as patents, real estate ownership or uniform commercial code filings).
Along these lines, our next-generation finance analytics benchmark research shows that companies have limited access to information about markets, industries and- economies.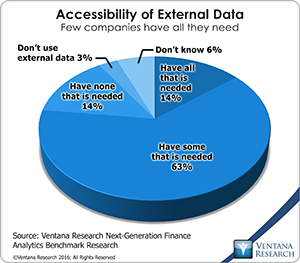 Only 14 percent of participants said they have access all the external data they need. Most (63%) said they can access only some of it, and another 14 percent said they can’t access any such data. In the past, this lack of access was even more common, but the Internet changed that. And this type of external data is worth going after, as it can help organizations build better models, perform deeper analysis or do better in assessing performance, forecasting or gauging threats and opportunities.
Only 14 percent of participants said they have access all the external data they need. Most (63%) said they can access only some of it, and another 14 percent said they can’t access any such data. In the past, this lack of access was even more common, but the Internet changed that. And this type of external data is worth going after, as it can help organizations build better models, perform deeper analysis or do better in assessing performance, forecasting or gauging threats and opportunities.
Cryptic data poses a different set of challenges than big data. Making big data usable requires the ability to manage large volumes of data. This includes processing large volumes, transforming data sets into usable forms, filtering extraneous data and code data for relevance or reliability, to name some of more common tasks. To be useful big data also requires powerful analytic tools that handle masses of structured and unstructured data and the talent to understand it. By contrast, the challenge of cryptic data lies in identifying and locating useful sources of information and having the ability to collect it efficiently. Both pose difficulties. Whereas making big data useful requires boiling the ocean of data, cryptic data involves collecting samples from widely distributed ponds of data. In the case of cryptic data, automating data collection makes it feasible to assemble a mosaic of data points that improves situational awareness.
Big data typically uses data scientists to tease out meaning from the masses of data (although analytics software vendors have been working on making this process simpler for business users). Cryptic data analysis is built on individual experience and insight. Often, the starting point is a straightforward hypothesis or a question in the mind of a business user. It can stem from the need to periodically access the same pools of data to better understand the current state of markets, competitors, suppliers or customers. Subject matter expertise, an analytical mind and a researcher’s experience are necessary starting capabilities for those analyzing cryptic data. These skills facilitate knowing what data to look for, how to look for it and where to look for it. Although these qualities are essential, they not sufficient. Automating the process of retrieving data from sources in a reliable fashion is a must because, as noted above, the time and expense required to acquire the data manually are greater than its value to the individual or organization.
Almost from the dawn of the Internet, Web robots (or crawlers) have been used to automate the collection of information from Web pages. Search engines, for example, use them to index Internet pages while spammers use them to collect email addresses. These robots are designed and managed by information technology professionals. Automating the process of collecting cryptic data requires software that business people can use. To make accessing cryptic data feasible, they need “data drones” that can be programmed by users with limited training to fetch information from specific Web pages. Tools available from Astera ReportMiner, Connotate, Datawatch, import.io, Kofax Kapow and Mozenda are great examples on where you can get started for leveraging cryptic data. I recommend that everyone who has to routinely collect information from Internet sites or from internal data stores that are hard to access or who thinks that they could benefit from using cryptic data investigate tools available for collecting it.
Regards,
Robert Kugel – SVP Research

Robert Kugel
Executive Director, Business Research
Robert Kugel leads business software research for ISG Software Research. His team covers technology and applications spanning front- and back-office enterprise functions, and he runs the Office of Finance area of expertise. Rob is a CFA charter holder and a published author and thought leader on integrated business planning (IBP).








