

The application of artificial intelligence (AI) and machine learning (ML) to business computing will have a profound impact on white collar professions. This is especially true in heavily rules-based functions such as accounting. Companies recognize the transformational potential of AI and ML, but the progression and pace of the adoption of these technologies is unclear. Some applications of AI and ML are already in use but others are a decade or more away from replacing human tasks.
For several years, I’ve asserted that AI and ML will have a profound impact on white collar work, especially in finance and accounting departments. I’ve estimated that the use of these technologies has the potential to eliminate one-third of the accounting department’s workload. My colleague David Menninger recently observed that this is the year of machine learning.
Companies have already successfully applied AI and ML to a variety of uses, for example, in fraud detection. Some consumer-facing business routine automation is in daily use. But other applications of AI and ML are likely to evolve step-by-step over a decade or more. Moreover, within a given field advances in the application of AI and ML won’t be uniform. In accounting, for instance, the automation of largely mechanical tasks such as invoice matching are within grasp while more complex ones that require more judgment are not.
It would be a mistake to extrapolate the significant progress already made in the application of AI and ML in some fields to others. A computer that can beat human champions at chess and go is a remarkable achievement. However, a computer cannot yet automate the accounting close or make preferred airline reservations when told the travel date and destination. Samuel Johnson’s quip, “a horse that can count to ten is a remarkable horse, not a remarkable mathematician,” is a cautionary note because words aren’t numbers and generally don’t work well in formulas and algorithms.
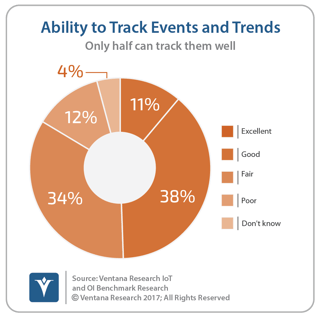
And companies aren’t necessarily able to track the data they need for machine learning. Our Internet of Things and Operational Intelligence research found that just fewer than half (49%) of organizations rate their ability to track events and trends in their systems as either excellent or good.
 Machine learning developed from numerical data sets isn’t simple but it’s more straightforward than working with words. Natural language processing (NLP) is likely to be the key technology driving advances in the application of machine learning for business software. Advances in this field over the past decade have been significant but there’s still much that must be achieved before the lights are turned out in an accounting department.
Machine learning developed from numerical data sets isn’t simple but it’s more straightforward than working with words. Natural language processing (NLP) is likely to be the key technology driving advances in the application of machine learning for business software. Advances in this field over the past decade have been significant but there’s still much that must be achieved before the lights are turned out in an accounting department.
One way of assessing the practical ability of NLP to drive automation in business applications is with an ambiguity-consequences framework. This can be thought of as a simple two-by-two matrix, with one axis designating degree of ambiguity of the language the application is likely to encounter and the other axis representing low and high consequences of errors. The degree of consequences is a function of the severity of the impact of an error and the probability that it will happen. Situations that have low ambiguity and minimal decision consequences are ripe for automation. In these circumstances, either the scope of the routines to be automated is clear (that is, there are established rules) or inferences and analogies provide a high probability the program makes the right choice. And even if the system makes the wrong choice, the “cost” of the machine learning is low. When this sort of routine is run frequently the system can be trained quickly.
As a result, chatbots designed for a narrow purpose are in the lower left of the matrix. While encountering them may cause some frustration for a small percentage of users when they are initially launched, if the chatbot is designed to perform a very specific task or small set of tasks and the ambiguity of the written or spoken words is low, the negative consequences of the occasional failure of the system to perform as expected by the user will likely be minimal.
Middle-ground fields such as medicine and health care have a large language set with precise definitions and thus low ambiguity. For instance, words like lipodystrophic, femur and Paget’s disease can be easily linked via medical literature to outcomes, treatments and other actions. Machine learning in medicine is helped by such specificity. Yet there are many other words used in a medical or health care application that must be learned in the proper context to avoid ambiguity and the consequences of being wrong are relatively high. And this is just English.
The upper right quadrant of this ambiguity-consequences matrix represents situations where there is high ambiguity and a high cost of a wrong choice. Ambiguity may be high simply because the meaning of words isn’t clear. The English language is quite nuanced and therefore prone to ambiguity, sometimes because of regional differences. The hood of a car in the U.S. is the piece covering the engine, while in the U.K. it’s the convertible top.
High ambiguity also may exist because there are many choices that the system can make. Sometimes the consequences of the choices either aren’t known or there is only limited experiential data from which to draw conclusions, compounding the challenge. If arriving at a course of action involves multiple steps, ambiguity can grow exponentially.
Especially in fields that are in the upper right quadrant of ambiguity and consequences, the path to full automation is likely to be slow. Yet artificial intelligence and machine learning will make steady inroads in enterprise systems even if these efforts fall far short of full automation. The value AI and ML systems provide in this intermediate period will be in steadily improving the productivity of professionals and knowledge workers. I’m reminded of the 1957 movie Desk Set. The plot revolves around a broadcast network installing a computer that would be able to do fact checking and research. (Of course, it would be about 40 years before this would become practical using something called a search engine connected to the internet. But I guess it seemed plausible at the time.) The plot line was that the librarians who were responsible for fact checking and inquiries thought the computer was designed to put them out of a job. In the end, they learn that the machine was intended to make them more productive.
It’s quite possible that the transition to the practical application of machine learning and artificial intelligence to rules-based enterprise routines will take a decade or more and that along the way corporations will find it necessary to keep a significant percentage of their accounting department staffs around. The finance department headcount may not change. The job descriptions and the department’s role certainly will.
Artificial intelligence and machine learning for business applications are bright and shiny technology objects that engender visions of an efficient, automated workplace of the future – visions sometimes colored by starry-eyed optimism. An informed discussion of the best path forward requires evaluations of how and when these technologies will be applied and to what effect. The underlying technology and theoretical constructs of natural language processing are quite complex. Some applications of the technologies are here now while others are a long way off. Business users can wait for the breakthroughs to come to them – some already have, although many with asterisks. Software and technology vendors don’t have the luxury of waiting for a technology application that’s been beta tested and is known to be a sure thing. Software companies that make early investments in AI and ML and proceed with due diligence are likely to be ahead of those that wait.
Regards,
Robert Kugel
Senior Vice President Research
Follow me on Twitter
and connect with me on LinkedIn.
Authors:

Robert Kugel
Executive Director, Business Research
Robert Kugel leads business software research for Ventana Research, now part of ISG. His team covers technology and applications spanning front- and back-office enterprise functions, and he personally runs the Office of Finance area of expertise. Rob is a CFA charter holder and a published author and thought leader on integrated business planning (IBP).








